たーのしー! P-NP問題 【ICONサマーブログリレー2019 8日目】
この記事は ICON サマーブログリレー2019 8日目の記事です。
本記事では読者がプログラミングに関して非常に基礎的な知識だけ持っていると想定しています。
プログラミングだといっても、簡単な英語だけ (if, else...) 知っていれば解釈できる内容なのであまりビビらなくても大丈夫です。
専攻している方のための追加内容 ( 青チャートだとすれば発展問題ですかね ) は紫にしました。ちょっぴりハードなので、難しそうだったら飛ばしても結構です。
一応母国語で書いて日本語に翻訳しています・・・つまり、ほぼ記事2回分です。
間違った内容・文法ミスがあったら、ご指摘いただけると幸いです。
0.序論
こんにちは、ICONのああああと言います。
編集していた途中 CHROME が急にエラーを起こしちょっと遅くなりました。
申し訳ございません・・・

今日は、コンピューター工学で最も有名な難題、いわゆる数学界のラスボス:
P-NP問題 についてお話しします。
2019年現在、グリゴリー・ペレルマンによって解決されたポアンカレ予想を除いては
いまだに証明されてないミレニアム問題で、賞金100万ドルです。
「100万ドルを稼ぐ最も難しい方法」とも呼ばれてますが、
ミレニアム問題の中では理解しやすいんじゃないかなーと思います。

他の問題はこんなことばっかりなんですからね。流石に無理。
1.予備知識
なるべく余計なことを減らしてページを閉じてしまう不祥事を防ごうとしたんですが
本題に入る前に、必要な2つの概念について軽く説明します。
(無責任な発言ですが) 皆さんなら十分理解できる内容ですし、完璧な理解…ではなく意味だけ大まかに知っていればいいので、軽く読んでください。
もう一度言いますが、紫は熟練者向けの説明なのでパスしても結構です。
1ー1 〉 時間複雑度と多項式時間
ある問題を見て易しい、あるいは難しいと判断する基準は何でしょうか。
状況によって違うんですが、時間がどのくらいかかるか、をよく考えますね。
問題を見てすぐ答えが浮び上がったら、簡単な問題。
多少真剣に悩んでこそ、答えが出る問題は難しい問題だと言えるでしょう。
コンピューター工学でも同じです。コンピュータを使って何らかの計算問題を解決するためには、アルゴリズムというものをコンピュータに教えてくれる必要があります。
その時、このアルゴリズムを通じて問題を解決するのにかかる時間で問題の難易を判断します。
「 アルゴリズムって何? 」
アルゴリズムとは、問題を解決するための手順や方法のことです。
あなたが 「牛乳を買って家に戻る」 ことを目標にしたとしましょう。
では、家を出て、赤信号だったら止まり、スーパーに牛乳がなかったらコンビニへ行く・・・ など、
目標を達成するための一連の過程がアルゴリズムです。
あまり効率的ではないですが、家からタクシーで駅まで行って、新幹線に乗って東京から牛乳を買って来る 方法もあるでしょう。
一つの問題を様々なアルゴリズムで解くことができるのです。

ここで、アルゴリズムごとに効率が異なるため、
いかに早く問題を解けるかの尺度として 時間複雑度 という概念を使います。
( 注. メモリをどれくらい使用するかの尺度として空間複雑度という概念も使いますが、一般的にメモリの使用量よりは速度を重視する場合が多いので時間複雑度を主に使います。)
時間複雑度という名前から分かるように、
早いアルゴリズムを持っている問題は 「 易しい (tractable) 」
遅いアルゴリズムを持っている問題は 「 難しい (intractable) 」 と表現します。
/* < 「早い」 の基準>
正確に言えば、「早い」 ということの基準は時間というより、総演算回数です。
厳密に言えば
易しい問題というのは多項式時間アルゴリズムが存在するということ、
難しい問題というのは多項式時間アルゴリズムがないことを意味します。
多項式時間についてはすぐ下で説明します。*/
そして、この時間複雑度、つまりデータの数によって演算回数がどのぐらい変化するかを関数化し、アルゴリズムの難易を直接的に比較します。
例えば、データ1個で演算回数が1回、データ2個で演算回数が4回 ・・・
こんな風にデータ数の二乗分だけ演算をするアルゴリズムがあるとすれば、
データ n 個を入れたときの時間複雑度関数は n^2 です。
一般的に、あるアルゴリズムが
多項式時間に解ける (= 時間複雑度が多項式以下 ) と易しい問題、
多項式時間に解けない (= 時間複雑度が指数式などの超越関数 ) と難しい問題です。
「 多項式時間? 」
文字通り、時間複雑度関数が多項式の形をしているという意味です。
つまり、「 多項式時間内に動作する (解ける) 」 の意味は
時間複雑度が O(n^2) や O(n^3) など、O(n^k) の形で表現できることです。
(あの O って何?という気がしたら、すぐ下の 余談2 を見てください。)
「 多項式時間がかかる 」 ということは問題を解くのに時間が相対的に少なくかかるという意味であり、これは易しい問題に分類します。
「 多項式時間より長くかかる 」 場合、超多項式時間 ( 指数関数時間など ) がかかると表現し、難しい問題に分類します。
入力の大きさが 100 だとすると、
時間複雑度が n^2 なら 100^2 秒、約3時間でなんとかできますが、
時間複雑度が 2^n のような指数関数の形になれば 2^100 秒です。
これは宇宙の年齢より長い時間ですよ。さすがに無理ですね。
/* <多項式時間の定義>
正確な定義はこうです。
「 ある問題を計算するのにかかる時間 m(n) が、問題の大きさ n の多項式関数より大きくないこと 」 ???
= 入力 n に対する時間複雑度が多項式以下で構成されているという意味です。
Big-O 記法ではもっと簡単に m(n) = O(n^k) です。ここで、k は問題によって異なる定数 */
<余談:早いものはいつも正解?>
「 データ数によってアルゴリズムの効率が変わる 」 ので、「早い」 というのも相対的です。
また、安定的な性能のアルゴリズムの場合、実装の難易度が高い場合が多く、便宜のため他のアルゴリズムを選択する場合もあります。
つまり、(効率の) 良いアルゴリズムだからと言ってそれ以外のアルゴリズムは捨てられるのではなく、状況によって選択します。
<余談2:時間複雑度と Big-O 記法>
データを n だけ入れたとき、演算回数が n^3+n+1 回なら、このアルゴリズムの時間複雑度関数 T(n) は n^3+n+1 だと言えるでしょう。
T(n) = n^3 + n + 1
ところで私たちが知りたいのは 「 資料の量によって演算速度がどれだけ変化するか 」 という変化量で、具体的な数値ではありません。なら、+1 程度は 軽く消しても大丈夫ではないでしょうか。
T(n) = n^3 + n
もう少し直観的です。そんな考え方だと、n^3 に比べ n の影響力は非常に小さいから、これさえ消してしまってもいいでしょうね。
T(n) = n^3
でも今回はちょっと気になります。定数は変わらないので変化量にはあまり影響をしないと思いますが、変数まで消してしまっても大丈夫でしょうか。
実際、n にさらに大きな数を入れると、n^3 + n で n が占める割合は n が大きくなるほど限りなく小さくなります。n が 1 や 10 ぐらいだったら結構ありますが、10万、100万を超えれば、ほとんど点と同じような存在になります。普通に考えても、結構大きいプログラムならデータの数が 10 個よりは多いですね。
このようにアルゴリズムの効率を示すため、時間複雑度関数の最も影響力の大きい項だけを表したものを Big-O 記法といいます。大文字 O を使って表記するのであんな名前が付けられました。
時間複雑度 T(n) が多項式であれば、最高次数のみ Big-O になります。
上の T(n)=n^3+n+1 を Big-O で表すと O(n^3) ですね。 これは big-O of n^3 と読みます。
「 では 10000n^3 と n^3 も O(n^3) ? これはちょっと・・・ 」
前述したように私たちが注目すべきことは変化量です。
10000n^3 回と n^3 回。結局、値が違うだけで変化する程度は同じだから、Big-O 記法では二つとも O(n^3) です。
要するに、問題の難易を比較するために時間複雑度という概念を使い、これを表す代表的な記法が Big-O 記法です。
また、多項式時間は時間複雑度の関数が、多項式であること (指数関数などの超越関数形ではないことを) 意味します。
問題を解くのに時間があんまりかからないことを (現実的に可能な時間がかかることを) 多項式時間がかかると言う - 程度で考えても結構です。
1ー2 〉 (非) 決定性チューリングマシン
何か難しそうな言葉が大量に登場しましたが、
一つ一つじっくりと分解してみましょう。
まず チューリングマシン とは、名前からも分かるように機械です。
チューリングは考案者の名前であるアラン・チューリングから由来したもので、
長いテープに書かれた様々な記号を一定の規則に従って変える機械です。
計算する機械、つまりコンピューターの前身とも言えるでしょう。
もともと行動表に書かれている規則に従ってできることが決まっていますが、
人々は一つの仕事だけじゃなくすべての問題を解ける機械が欲しいようでした。ここで生まれた概念が普遍的なチューリングマシン ( Universal Turing Machine ) です。
「うーん、そうだったら チューリングマシン = コンピューター だよね 」
はい。少し差はあるんですが、理解するには無理のない説明です。
/*<チューリングマシンとコンピューターの違い>
前述した 「普遍的チューリングマシン」 とは、一つのチューリングマシンから任意のチューリングマシンをシミュレーション (真似る) できる機械のことです。
つまり、全てのチューリングマシンをまねることができる機械なのです。
現代のノイマン型によるコンピューターは普遍的チューリングマシン理論に基づいています。したがって、普遍的チューリングマシンは現代のすべてのコンピューターを真似ることができます。
チューリングマシンとコンピュータの代表的な違いの一つは、チューリングマシンは任意アクセスが不可能だというのことです。 つまり、テープの任意の位置を、すぐ接近できません。例えば、二分探索 (binary search) のようなアルゴリズムの場合、任意アクセスができれば O(logN) の時間複雑度を持ちますが、チューリングマシンでははるかに遅い O(N) の時間複雑度を持ちます。
また、あるコンピューターが普遍チューリングマシンと同じであれば、そのコンピューターはチューリング完全 (Turing complete) だと表現します。
ここで二つ目の違いは、現実のすべてのコンピューターはチューリング完全ではないということです。 その理由は、チューリングマシンのテープの長さが無限に増えることができるのに比べ、現実のコンピューターは記憶装置が有限であるからです。
もし記憶装置が無限であればチューリング完全であると言えます。これを緩いチューリング完全性 (Loose Turing Completeness) と定義します。 ほとんどのコンピューターは緩くチューリング完全なので、あるコンピューターができる仕事は、(十分な時間とメモリさえ与えられれば) どんな簡単なコンピューターでもできます。*/
ただし、チューリングはコンピューターの限界についても説明しました。
どんな究極のコンピューターでも解けない問題が存在するということです。
これがその有名な 停止問題 (Halting Problem) です。
停止問題について簡単に説明すると、
1つのプログラムと1つの入力を与え、これが有限な段階後に答えが出るか出ないか、解決する前にコンピューターが予め答えるのか (= そのようなアルゴリズムが存在するか) に対する問題です。
もっと簡潔には、これ解く前に答え教えてくれる? とコンピューターに聞いた時、コンピューターがその答えを出せるかを証明する問題ですね。
結果から言うと、そのようなアルゴリズムは存在しないと証明されています。
これはコンピューターがすべての問題を解くことは不可能であること (コンピューターには限界がある) を意味します。
「それ当然でしょう? 例えば、私はいつ死ぬかのようなものは誰でも解けないし。」
はい。しかし、それは最初から解けることができない問題で、
停止問題の核心は解けることができる問題の中にコンピューターには解けない問題が存在するということです。
これは、数学的な方法で全ての問題を解く一般的な手続きが存在しない (= 数学は完璧ではない) というゲーデルの不完全性定理ともかなり似ています。
/*<停止問題の証明>
C言語や他の言語を少しでも勉強した方なら十分証明できる内容です。
私たちが証明しようとするのは、停止問題を判別するアルゴリズムがない (= 全ての数学的問題をチューリングマシンで解くことは不可能) なので、
背理法を使用するため アルゴリズムが存在すると仮定 しましょう。
ではそのアルゴリズムとして exit (a,i) という関数 (= 停止問題を判別するアルゴリズム) を定義しましょう。ここで a は使われる任意のプログラムを、i は使われる任意の入力を指します。
この関数は、a が i という入力に対して停止し 結果を返還すると TRUE を、さもなければ FALSE を返します。すなわち、a のプログラムに i という入力を与えた場合、アルゴリズムが終わったら TRUE、終わらず無限ループに陥ったら FALSE を返します。
ここで関数 exit を矛盾させる関数を定義します。

*注意
subroutine は プログラムに自分自身を入力させる関数です。
例えば、s がコンパイラである場合、exit (s,s) は自分自身をコンパイルする中で無限ループに陥るかどうかを検査します。
また、よく見ると subroutine という関数は結果を覆します。 すなわち、
exit が無限ルーフに陥る場合、subroutine は正常に終了し、
exit が正常に終了する場合、subroutine は無限ルーフに陥ります。
そして最後に質問を投げます。
exit (subroutine, subroutine) は TRUE か? FALSE か?
複雑に見えますが (複雑です) ゆっくりついて行ってみましょう。
exit の定義により、
subroutine というプログラムに自分自身 (=subroutine) を入力値にあげた時の結果を聞いているので、
subroutine (subroutine) がこの結果を返還しているのか (= TRUE)
無限ループにはまるか (=FALSE) と同じ意味です。

① exit (subroutine, subroutine) が TRUE だとすれば、
subroutine (subroutine) が正常に終了し、結果を返却しなければなりません。
しかし、exit (subroutine, subroutine) が TRUE だと仮定したので、
subroutine の定義により else 文の無限ループに陥ります。
すなわち、無限ループに陥って FALSE となるので、TRUE にはなりません。(偽)
② exit (subroutine, subroutine) が FALSE だとすれば、
subroutine (subroutine) が無限ルーフに陥る必要があります。
しかし、exit (subroutine, subroutine) が FALSE であると仮定したので、
subroutine の定義により if 文の true をリターンしてプログラムが終了するこ
とになります。すなわち、結果を返還してプログラムが終了されたので TRUE
になり、FALSE にはなりません。(偽)
このように exit (subroutine, subroutine) は 真にも偽にもなれないので、矛
盾が発生しました。 そのため、最初から exit のような関数は存在しなかった
という結論に至ります。
すなわち、停止問題を解決するアルゴリズムが存在しないということです。*/
話が長くなりました。
それでは決定性チューリングマシンで 「決定性」 とは何でしょう。
文字通り、特定の状況でできることが一つに決まっているという意味です。
非決定性というのは次の段階が一つに決まっていない場合のことになりますね。

例えば、私たちがこんな形の分かれ道に立っているとしましょう。
各分かれ道の終わりには宝物があるかも、ないかもしれません。
ここで誰かが 「この中で宝物がある道は存在するのか? 」 と聞いたとします。
この問題の答えが Yes ということを知るためには、
宝物がある道をただ一つでも知っていれば結構で、他の道は見る必要ありません。
つまり、結果が Yes である場合が一つでも存在すれば、答えは Yes です。
すべての場合において結果が No だったら、答え は Noでしょう。
あなたが 「決定性チューリングマシンで宝物を探そうとした」 としましょう。
決定性チューリングマシンは分かれ道を同等の立場で見ることができません。
つまり、人間のように
「 よく分かんないから右にしよっかー 」
みたいな根拠のない選択は不可能です。(なぜ?という気がしたら余談を参照)
よって必ず与えられたアルゴリズムを通じて、順に分析しなければなりません。
もし左側から順番に道を調べるとプログラミングしたら、
一番左側から行って来ることを数十回繰り返さなければなりません。
運がよければ一度に見つけることもできますが、さもない場合、すべての道を
行ったり来たりしても宝物は見つからないんでしょう。
逆に、非決定性チューリングマシンは、この分かれ道を同等な立場で 「 選択 」 す
ることができます。 いわゆる 「 当てずっぽうで解く 」 こともできるのです。
これを 「 非決定性アルゴリズム 」 といい、各段階でその次の段階が唯一に決まら
ない場合を意味します。
要するに、次の行動が唯一に決まっている場合 (任意的要素がない) は決定性
チューリングマシン、可能性が複数存在する場合は非決定性チューリングマシン
です。
<余談:コンピュータはランダムを知らない>
ところで、さっきコンピュータは任意の選択ができないとか言ってましたね。
マインスイーパーを例に挙げてみましょう。 コンピュータがいくら実力があっても、最初にスタートするときや、表示された数字上、地雷の出るところが明確でない場合など、いつかはいずれかを 「 当てずっぽうで 」 解く必要がある状況が存在します。 運が悪ければ、数百個のタイルの中で地雷タイルを選び、開始と同時に終わるでしょう。 ところで、 「 当てずっぽう 」 ということは、非決定性チューリングマシンだけ可能です。
( 実は、Windows 内臓マインスイーパーの場合、最初には地雷タイルを絶対に選べないようになっています。)
/* <マインスイーパーを解くプログラム>
「 イメージを認識し、マインスイーパーを解くプログラム 」 のコードです。

コードを見れば分かると思いますが、数字を見て計算するのではなく、必ず地雷の位置が確定される 「確定パターン」 をすべてイメージ化し、「パターンによって決まる」 選択をさせています。
unknownCellExists という関数は、タイルのイメージを分析し、まだクリックしてないタイルがあると、TRUE を返します。この unknownCellExist という関数が TRUE である間、( = クリックしてないタイルが存在すれば )、マインスイーパーの確定パターンを保存した patterns というリストからイメージを呼び出して比較します。もし、確定パターンが存在したら、右クリックで地雷を表示し、なければ random.choice を通じてランダムでクリックします。 地雷が爆発すると、プログラムが終了します。
「ちょっと待って、さっきランダムな選択ができないって言ったでしょう?」
PYTHON は非決定性アルゴリズムをサポートしません。random.choice はすでに生成されている長い擬似乱数列からリストを受け取り、一つずつ呼んでくる役割をするだけです。(擬似乱数についてはすぐ下を参照)
実行してみればわかるんますが、このアルゴリズムは初級でしか作動しません。それにもかかわらず、かなり失敗率高いです。*/
「 コンピュータが勝手に選択するようにすればいいじゃん 」
一応 どうやって勝手に選択させるか を考えてみましょう。コンピュータは徹底的に数字と計算を利用して作動する機械であるので、コンピュータに無作為に何かを選ばせるためには無作為に数字を生成する必要があります。
しかし残念ながら、一般的に決定性チューリングマシンは完全な乱数 (ランダムな数) を生成することはできません。決定性チューリングマシンは、特定の入力が与えられた時、いつも同じ過程を経て、いつも同じ結果を出すので、同じ入力に出力が変わる乱数は、根本的に生成が不可能なのです。
でも、それはちょっと変です。 私たちはゲームなどでよく乱数が必要な状況によく会います。それなら私がガチャで爆死してしまったのも切ない確率の結果ではなく、ゲーム会社のよからぬ意図が存在したということでしょうか。
そうかも知れませんが、一般的にコンピュータは擬似乱数 (pseudorandom numbers) というものを使ってランダムな数を生成します。
擬似乱数とは、乱数ではないが乱数扱いが可能な数列の意味で、擬似という言葉からもわかるように完璧な無作為ではないので、結局何らかのパターンを見つけることができます。
つまり、よく見るランダムは本当に任意の値ではなく、特定の方法で計算したり、ms 単位で時々変わる値を初期値とし様々な計算過程を経て、まるで任意の値のように見えるのです。
ここでこの擬似乱数の核心は、「シード値が同じなら全く同じ結果が出る」ということです。シード値とは、簡単に言えば乱数を作るために使われる材料のようなものです。プログラムの乱数発生器は、多数の乱数表から一つを選んで擬似乱数を生成する方式ですが、この計算で使用される値がランダムシードです。
結局、本質的に乱数表が有限な以上、シード値も固定されているし、擬似乱数であっても同じ順番に、同じ数字が出る可能性があるということです。
ただし、今はシード値で 「現在の時間」 のように変わり続けている数を使うので勝手に操ることができないし、CPUが持っている乱数表の量が非常に多いため、人が見る時はほとんど 「無作為」 に見えます。
こう言えば簡単に拵える、必要もない数だと思うかも知れませんが、
実は現実を再現するのが目的ではないプログラミングの場合、完全な乱数より擬似乱数がもっと有用に使われます。同じシードは同じ結果を呼ぶため、むしろこれを逆利用し、ネットワークゲームのプレーヤー間同期化、リプレイモード具現など、多様なところで使っています。
とにかく、決定性チューリングマシン − 私たちが使ってるコンピューターでは完璧な乱数を作ることはできません。つまり、任意の選択が不可能です。
もちろん、乱数の生成だけが目的であれば、特殊ハードウェアを装着して周辺環境のノイズをセンサーで捉え、乱数を生成するといったすごい方法もあります…が、これさえもブラックホールの内部のように超極端な環境である場合、ランダムシードが固定されます。
<余談2:モンスターボールの秘密>
ポケモンでモンスターボールを投げてから3回揺れると、ポケモンが捕れます。
つまり投げる時も含めて捕獲チェックを4回すればポケモンが捕れますが ( 5世代以降からは 「捕獲クリティカル」 のように捕獲チェックを一回だけするシステムも存在)、この揺れる回数も、擬似乱数を通じて決定されます。 例えば、
3、4世代:Catch = (220-24) / { (224-216) / CatchValue) } 0.25
6世代:Catch = 65536 / (255 / a) 0.1875
3、4、6世代の捕獲処理の公式は以上のようになっており、モンスターボールが揺れるたびに、 0 から 65535 (2byte) までの乱数を生成します。この乱数が上の Catch という値より大きい場合、捕獲は失敗します。一方、乱数が上の Catch 以下の場合、再びモンスターボールを揺らせ、新たな乱数を生成する過程を3回繰り返します。(最初のチェックに失敗したら、一度も揺れなく、すぐポケモンが出ます。)
2.P-NP問題とは?
さて、ついに記事の本題です。
ざっくり言えば、P-NP問題は
簡単に検算できるすべての問題はすべて簡単に解けるのか? です。
つまり、クラスPと クラスNPは 同じか?であることを証明する問題です。
「 ちょっと、クラスP • クラスNPって何? 」
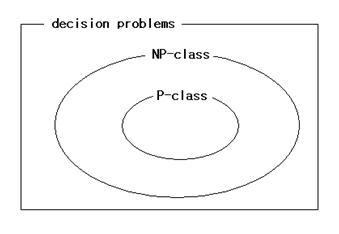
ここで P と NP は、いずれも決定問題の分類に該当します。
P 問題を集めたのがクラスP 、NP 問題を集めたのが クラスNP です。
決定問題とは、答が YES あるいは NO と出る問題を指します。
例えば、A と B は互いに疎か? という問題は
答えが YES または NO なので決定問題、
集合 C の部分集合の個数は? という問題は
YES または NO では答えられないので決定問題ではありません。
では P 問題、NP 問題はまた何でしょうか。簡単に言えば、
P (Polynomial) 問題 : 決定問題の中、簡単に解けるものを集めた集合。
NP (Non-Polynomial : NOT Pではないです。) 問題 : 決定問題の中で簡単に解けるかは分からないが、ヒントが与えられれば少なくともその答えが正しいか確認できる問題を集めておいた集合。
となります。
/*<P 問題と NP 問題の厳密な定義>
P 問題と NP 問題の学問的な定義は次の通りです。
P (Polynomial) 問題:
決定性チューリングマシンを使って多項式時間内に解けることができる問題。
NP (Non-Polynomial) 問題:
1.非決定性チューリングマシンを使用して多項式時間内に答えを求める問題。
2.Yes という根拠が提示された際、決定性チューリングマシンでそれが正しいということを多項式時間内に確認できる問題
ちょっと難しく書いていますが、読んでみたら結局三つの定義が上の説明と同じ意味だということが分かります。
NP 問題の 1番目、2番目の説明も同じ意味です。
非決定性チューリングマシンで多項式時間内に解くことができるとは、
決定性チューリングマシンでは指数式時間がかかる (もっと長くかかる) という意味です。
現在としては決定性チューリングマシンでは Yes という根拠が提示された時、多項式時間内にそれが正しいことを確認するだけで、決定性チューリングマシンでも多項時間内に解けるかは分からないということを意味します。
なお、一般的に決定性チューリングマシン (TM) で多項時間内に解ける決定問題は、非決定性チューリングマシン (NTM) でも多項時間内に解けることが証明されています。
問題は、逆に NTM で多項時間内に解けるすべての問題が、TM でも多項時間内に解けるのかということで、これが P - NP問題の始まりです。*/
「 簡単に解けるなら、答えが正しいのかも簡単に確認できるのでは? 」
お見事です。ヒントを受けてその答えを確認できるのが NP 問題なら、
ヒントをもらわなくても答えが正しいか確認できる P 問題も NP 問題です。
飛行機に乗らなくても (= ヒントがなくても) 1時間以内に行ける距離は、飛行機でも (=ヒントが与えられても) 1時間内に行くことができますよね。
実際、P 問題は NP 問題に含まれることがすでに証明されています。
すなわち、P 問題なら NP 問題です。
「ではざっくり言って P は簡単な問題だと思えばいいでしょう? では、NP は難しい問題になるのかな。」
いいえ。クラス P が クラス NP に属しているので、P 問題も一応 NP 問題です。なので、NP が難しい問題だという説明は何か違う気がします。
正確に言えば P 問題は易しい問題で、
NP 問題は難しそうだが、実際に易しい問題か難しい問題かはまだ分からない問題です。
例を挙げてみましょう。
39,004,583という自然数は素因数分解可能か? という問題があるとしたら、
この問題を解くにはかなり(?) 時間がかかりますよね。
(そもそも、デジタルコンピュータで自然水を素因数分解する多項式時間アルゴリズムはまだ存在しません。これが RSA とも呼ばれる暗号化方式に使われます )
ただ、39,004,583 が 5557 と 7019 という二つの少数の積だということを知っていれば、他の数を確認する必要もなく、答えは Yes というのをすぐ確認できます。
つまり、この問題はヒントが与えられたときに正解が正しいか簡単に確認でき
たので、NP 問題です。
だが、ヒントがなくても簡単に解けるかがまだ明らかになっていないで、P問題
(= やさしい問題) なのかは分かりません。
また、ヒントが与えられたら答えを確認することができるので、難しそうなんだ
けど一応解ける問題という意味ですよね?
つまり P 問題と NP 問題は全部 「解ける」 問題です。
( 決定性チューリングマシンでも解けます。ただ、現実的に不可能な時間がかかるだけです。あるコンピューターができる仕事は、十分な時間とメモリさえ与えられればどんな簡単なコンピューターでもできます。と言ってましたね?)
ここで、人々はひらめきました。
「 一応 P 問題が NP 問題に属していることは明らかだから、もし NP= P なら
結局 NP 問題も簡単に解けるんじゃない? 」
とても重要だからもう一度まとめましょう。
我々はこれに先立って、全ての P 問題が NP 問題であること、すなわち
P が NP に含まれていることを突き止めました。P 集合は NP
集合より小さいか同じだという意味です。
しかし、NP が P と同じなのか、もっと広い範囲なのかは知りません。
すべての P 問題が NP 問題というのは、
解きやすい問題は、ヒントが与えられれば (あえて与える必要はありませんが) 答えが正しいか確認できるという意味です。
では逆に、すべての NP 問題は P 問題でしょうか? 言い換えれば、
全ての検算可能な、つまりヒントが与えられたら答えが正しいか確認できる問題は解きやすいのでしょうか。
これが、待望の P - NP 問題です。
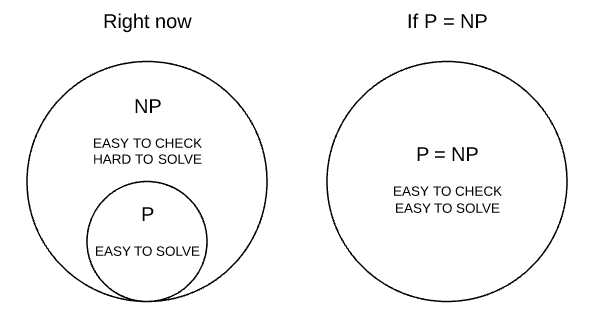
P と NP が同じであれば、NP 問題が実は P 問題であった、すなわち簡単な問題だったということが明らかになるので、上記の例示のように難しそうな問題も、ヒントなしで簡単に解ける方法が存在するという話になります。
/* <アルゴリズム的側面>
すなわち、すべての NP 問題は P 問題に変換できるアルゴリズムが存在するという意味であり、これはすべての NP 問題が決定性チューリングマシンで多項式時間内に解けるという意味です。*/
ただ、全ての NP 問題がすぐ解決できるようになるという意味ではありません。
P = NP が意味することは、多項式時間内に解けるアルゴリズムが存在するという意味で、このアルゴリズムが何かについてはまったく教えてくれないからです。
逆に P ≠ NP だと、ある問題は非常に難しい (= 多項式時間アルゴリズムが存在しない) ということを意味します。多項式時間アルゴリズムを見つけるため無駄な苦労をする必要がないという意味です。
(ただし、P ≠ NP は、全ての NP 問題を変換できないという意味で、ある NP 問題は P 問題に変換できるかもしれません。ここで非常に難しい問題というのは主に NP-Complete のことですが、これに対しては後述します)
どちらであれ証明すれば、賞金100万ドルとともに数学、暗号学、統計学などの関連分野の教科書にあなたの名前が載るようになります。
ちなみに、本質的に証明は検証より難しいと考えられるので、P = NPが直感的ではないという理由から大多数の専門家たちは P ≠ NP だろうと予想しています。
ここまで読んだ人は P - NP 問題の大まかな理解が終わったと言えます。
3.NP完全問題 ( NP-Complete )
ここまでが P - NP問題を理解するための説明だったとすれば、
これからは P - NP問題を解決するための説明です。
人々は P - NP問題の答えに近づくために NP-完全 という概念を考えました。
「NP 問題の中で最も難しい問題を簡単に解けるなら、
どの NP 問題でも簡単に解けるはず」
つまり、
「もしその最も難しい問題の中で一つでも P 問題なら、
すべての NP 問題が P 問題になるのではないか」
と思うようになったのです。ここで、
NP 問題の中で最も難しい問題を NP-完全 ( NP-Complete )と言います。
ちなみに、少なくとも全ての NP 問題ほど (全ての NP 問題以上) 難しい問題ではあるが、NP集合に属するかどうかはまだ分からない場合、NP-困難 (NP-Hard) といいます。
「え? でも、問題ごとに解き方違うじゃん。一つの問題を解いたからといって、他の問題まで全部解けるの?」
それが NP 問題の面白い性質です。NP で分類された問題は互いに関係ないように見えますが、実は一つに集めれます。ある問題 A を解いた時、そのアルゴリズムを利用して間接的に B も解けるのです。
( 詳しい説明は、すぐ下の還元 (reduction) を説明するときします。)
「 NP-complete は なんとかなるそうだけど、NP-hard はよくわかんない 」
当たり前です。難しいパートなんですからね。定義を見てみましょう。
「 クラス NP に属する全ての問題を多項式時間内にある問題 Q に還元することができれば、その問題 Q は NP-Hard である。」
もう読むのも嫌になりますが、ゆっくり見てみましょう。
クラス NP、多項式時間... 一応全部知っている言葉ですが、耳慣れない言葉が一つあります。還元 (reduction) です。
還元とは、一つの問題を利用して他の問題を解くことを意味します。
例えば、次の二つの問題が与えられたとしましょう。
問題 A:与えられた n 個の数字を大きさ順に整列する問題。
問題 B:与えられた n 個の数字の中間値を計算する問題。
ある人が問題 A を簡単に解けるなら、問題 B も簡単に解けるはずです。
なぜなら、与えられた数字を整列すると真ん中の数が中間値になるからです。
このように A を解くことができるアルゴリズムで B を解いた場合、
問題 B を A に還元したと表現し、これは問題 A の難易度が B の難易度よりも高いことを意味します。
( 理解づらいなら、12 * 5を計算するとしまょう。一見すると掛け算の方が難しそうに見えますが、掛け算は足し算の繰り返しなので、足し算ができれば掛け算もできることは当然です。つまり、足し算で掛け算を解いたので、足し算が掛け算より難しい (足し算で掛け算以外も解けるから) ものになるのです。)
これもダメだったら、還元はアップグレードだと思ってください。
B を A に還元したのは B を A にアップグレードさせたということだから、
当然 A は少なくとも B ほど難しいはずです。
( この表現が本当に重要です。 必ずしも難しいのではないので )
当たり前ですね、A にアップグレードをさせたところで
B より易しくなったら アップグレードではありませんから。。。
還元の意味が分かったので、文章を再度見てみましょう。
「 クラス NP に属する全ての問題を多項式時間内にある問題 Q に還元することができれば、その問題 Q は NP-Hard である。」
クラス NP の全ての問題を Qという問題に還元したので、せめて Q は 全ての P や NP 問題ほど難しいはずです (どうせ P 問題は NP 問題に属しているので、NP ほど難しいというのは P にも同様です)。英語その通りに、NP に対して Hard ですよね。
でも、それがクラス NP なのかはまだ分かりません。
もし NP-hard でありながら NP だったら、Qは NP-Complete です。
ちなみに、上記の停止問題は
NP-hard であるが、NP ではない (NP-Complete ではない) 問題です。
「停止問題は 「はい」 とか 「いいえ」 の形にしか答えられないから、決定問題じゃん。じゃあ何で NP ではないの。」
それは、停止問題を解くアルゴリズムがないため、つまりコンピュータが解けない決定問題だからです。NP 問題も解ける問題だと言いましたね。
既に SAT - 充足可能性の問題という NP-Complete を停止問題に還元できることが証明されており、NP-hard であることは正しいが、P 問題とNP 問題は両方とも解決可能な問題なので、停止問題は NP に属しません。
「 NP-Complete 問題を還元したとしたら停止問題が最も難しい問題だと言う意味?」
いいえ、違います。これ本当に重要な概念です。
さっき還元を説明するとき、Bほど難しい、
つまり必ずしも難しいわけではないと見飽きるほど強調しましよね。
ところでもし「お互いに還元できる」なら、SAT 問題も、停止問題も最も難
しい問題だと言えるんでしょう。
だから、NP の中で最も難しい NP-Complete を還元したとしても、その問題
が唯一の NP-Complete になるのではなく、この問題も NP-Complete に追加
されるのです。
実際、ある問題が NP-Complete であることを最も簡単に証明する方法は、す
でに知られている NP-Complete 問題をその問題に還元させることです。
もう終わりです。最初に戻りましょうか。
「もし NP 問題の中で最も難しい問題 「一つでも」 P 問題なら (= 簡単に解けるなら)、すべての NP 問題が P 問題になるのではないか」
「最も難しい問題一つでも」P 問題てあれば NP 問題の性質より、
還元を通じて全ての NP 問題を解くことができます。
つまり、( NP-Completeを含めた ) 全ての NP 問題が P 問題になります。
じゃーん! P = NPの証明終了!
これらをグラフでまとめると、次の通りです。
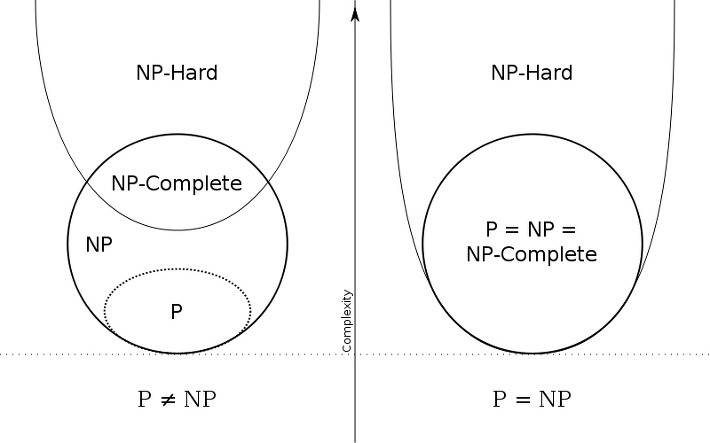
「 え?P = NP だったらすべての NP 問題を簡単に解けると言ってたじゃん。 P ・ NP ・ NP-Complete に属しない NP-hard ってなに?」
そもそも NP-Hard が NP なのかも分からないし、NP-hard は決定問題だけではなく非決定問題も含みます。つまり、コンピューターで解けない問題も含まれています。
もちろん、NP-Hard でありながら NP だったら (NP-Complete だったら) 解けます。
4.終わりに
実は 「 誰でも理解できる記事を書こう!」 と言う大げさなことよりも、
私の知識をまとめるために書き始めたんですが ...
気が気でないです。長いですね、これ。
私も勉強している立場なので、
間違った内容などがあれば是非、ご指摘お願いします。
「 P - NP問題についてもっと詳しく勉強したい!」 という方があれば、
Introduction to Algorithms というバイブル (?) をおすすめ。
英語が苦手だったら、一応日本語バージョンもありますよ。
えーと。ともあれ、長い文を読んでくださって本当にありがとうございます。

ハードル高いな・・・
xi 最高
[参考資料]
ENG)
https://en.wikipedia.org/wiki/P_versus_NP_problem
KOR)
https://dudri63.github.io/2019/02/04/algo33/
https://joshuajangblog.wordpress.com/2016/09/21/time_complexity_big_o_in_easy_explanation/
https://wkdtjsgur100.github.io/P-NP/
http://sicegorobot.blogspot.com/2015/10/p-np.html
https://candykick.tistory.com/5
https://zeddios.tistory.com/93?category=682196
https://ratsgo.github.io/data%20structure&algorithm/2017/11/30/NP/
http://suyeongpark.me/archives/tag/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98